BEST FOR LOCAL LLM EDITOR'S PICKNEW
NVIDIAGPUS
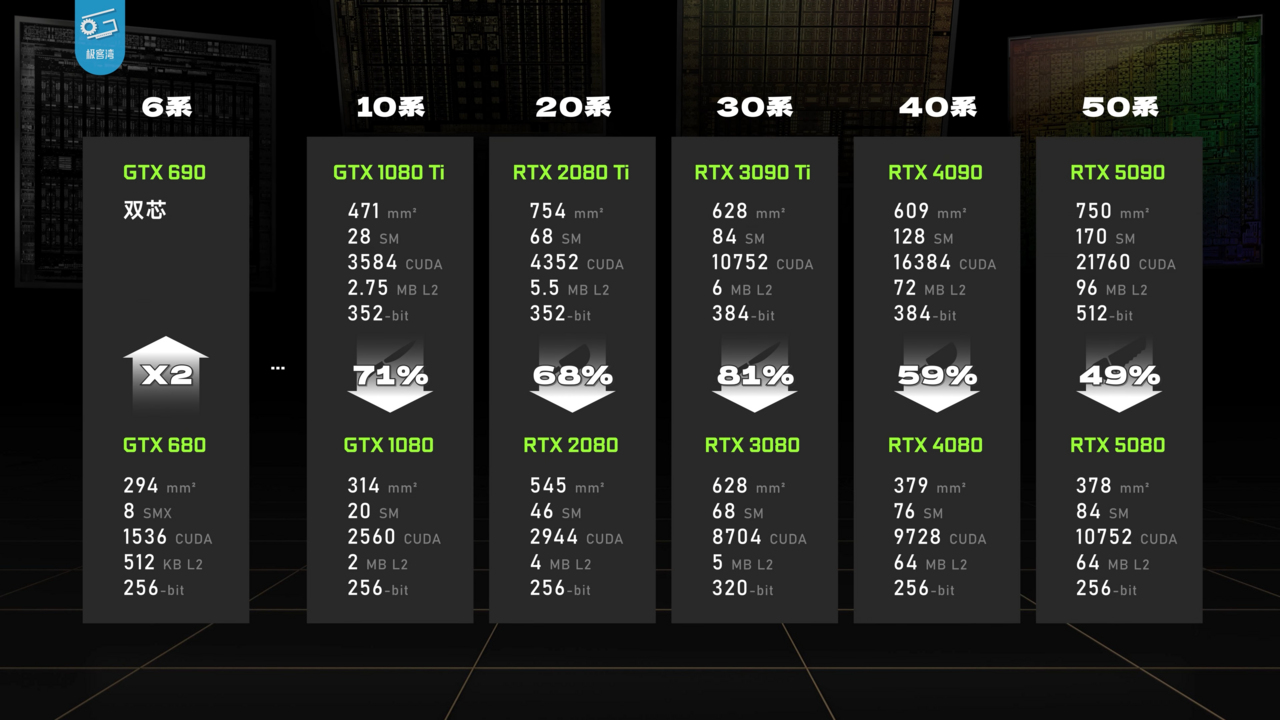
GeForce RTX 5090
32GB of GDDR7 at 1,792 GB/s makes the 5090 the highest VRAM consumer GPU shipping, fitting a full 30B model in fp8 or a quantized 70B with room for context.
- 21,760 CUDA cores, 170 SMs, Blackwell architecture
- 32GB GDDR7, 512-bit bus, 1,792 GB/s bandwidth
- 5th gen Tensor cores, 4th gen RT cores, DLSS 4
- 575W TDP, recommended 1000W PSU
- PCIe 5.0 x16, three DisplayPort 2.1, one HDMI 2.1b
AI USELocal LLMs up to 70B 4-bit quantized, 30B fp8, Stable Diffusion 3.5 and Flux at full resolution, single-GPU fine-tuning of 13B models.
$2,899 to $3,999
STREET, MAY 2026